How to Decide Which Cluster Is the Best One
There not be any overlap between clusters ie. Choose the number of clusters as the smallest value of k such that the gap statistic is within one standard deviation of the gap at k1.
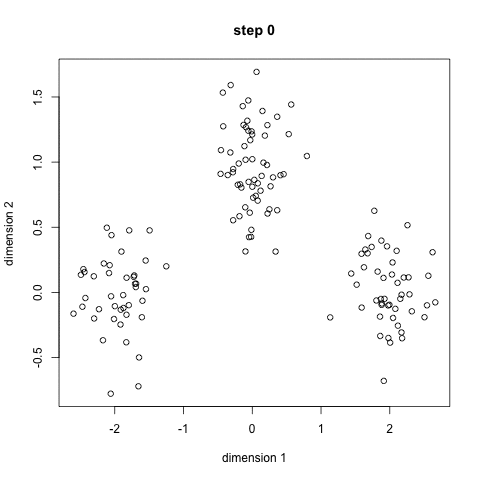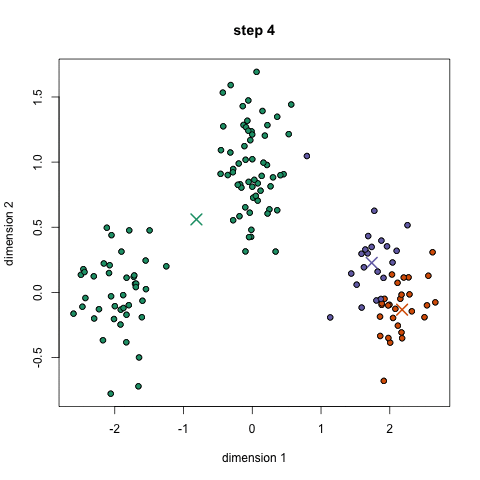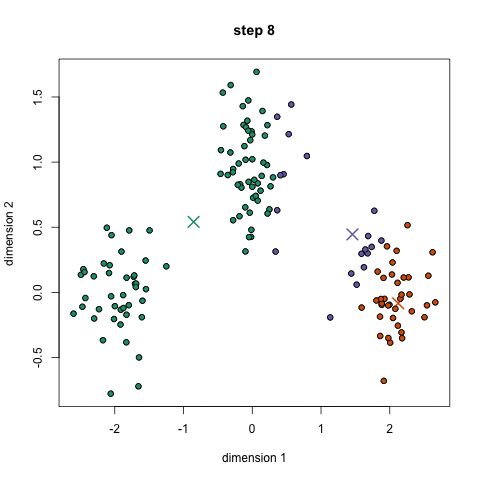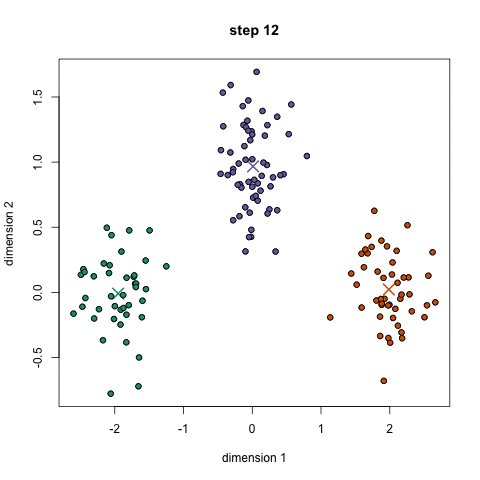
The 5 Clustering Algorithms Data Scientists Need To Know By George Seif Towards Data Science
Ideally each cluster should be a mini-representation of the entire population.

. We want to determine a way to compute the distance between each of these points. This exceeds 1000 so in this case the maximum would be 1000. The Best Introduction to Data Science Lesson - 2.
For example in a population of 5000 10 would be 500. Then we can calculate the distance between all the members in our example they are the counties that belong to each cluster and the center of each cluster every time we. One of them is called Elbow Curve We iteratively build the K-Means Clustering models as we increase the number of the clusters starting from 1 to lets say 10.
The top 5 ones are partition-based algorithms hierarchy-based algorithms fuzzy theory-based algorithms distribution-based algorithms and density-based algorithms. GapkGapk 1s k 1. Begingroup Most often internal clustering criterions some of which you mentioned are used to compare cluster solutions with different number of clusters K in order to select the best K.
Even in a population of 200000 sampling 1000 people will normally give. This is probably the most well-known method for determining the optimal number of clusters. Then perhaps you should go with X since the addition of 1 more cluster does not really add considerable value.
This method is inexact but still potentially helpful. Its the value that is circled with a red color. For this we try to find the shortest distance.
The best value for the number of clusters is the place where the curve breaks. There are various types of clustering algorithms. However in practice clusters often do not perfectly represent the populations characteristics which is why this method provides less statistical certainty than simple.
3 is the optimal choice for the clustering algorithm. After each clustering is completed we can check some metrics in order to decide whether we should choose the current K or continue evaluating. Accordingly the number of clusters might vary depending on the structure of the data.
A smaller cluster will also reduce the impact of shuffles. The compute memory and other resources on a given node vary widely based on the hardware profile of the server that creates the node. Here each data point is a cluster of its own.
A large cluster such as cluster D is not recommended due to. Having said that you might want to have a look at Dirichlet Processes. Another general rule If you find that X and X1 clusters are the best 2 options.
Finally the best sampling method is always the one that could best answer our research question while also allowing for others to make use of our results generalisability of results. A good maximum sample size is usually around 10 of the population as long as this does not exceed 1000. SPSS has no in-built computation of such indices along with its clustering routines with the exception of automatic K-selection in TwoStep clustering and computation.
Cluster best practices As you start creating clusters you may find that there is an overwhelming set of options and capabilities available for you to choose from. There are several key guidelines to decide how many Kubernetes nodes to include in a cluster. When we cannot afford a random sampling method we can always choose from the non-random sampling methods.
In a population of 200000 10 would be 20000. You need to define similarity measure on transactionpoints for which you can use the feature extraction mentioned above and Cosine similarity. Probably the most well known method the elbow method in which the sum of squares at each number of clusters is calculated and graphed and the user looks for a change of slope from steep to shallow an elbow to determine the optimal number of clusters.
What I would like to do instead is to merge clusters until a certain maximum distance between clusters is reached and then stop the clustering process. This video presents best practices for configuring clusters and highlights common scenarios you might encounter when you create your clusters. If stability is a concern or for more advanced stages a larger cluster such as cluster B or C may be a good choice.
Determine how many resources each node contributes to the cluster. In clustering there is often no one correct answer - one clustering may be better than another by one metric and the reverse may be true using another metric. For the last step we can group everything into one cluster and finish when were left with only one cluster.
And in some situations two different clusterings could be equally probable under the same metric. Note that using B 500 gives quite precise results so that the gap plot is basically unchanged after an another run. It is also a bit naive in its approach.
One method that works fairly well although tends to underestimate the actual number of clusters is to look at the within cluster similarity at each stage. To classify a new transactionpoint you need to first assign it to a cluster and pick close points to the point from the cluster and label based weighted majority voting. Calculate the Within-Cluster-Sum of Squared.
There are different methods stopping rules in doing this usually involving either some measure of dissimilarity distance between clusters or to adapt statistical rules or tests to determine the right number of clusters. The same people or units do not appear in more than one cluster. With sklearnclusterAgglomerativeClustering from sklearn I need to specify the number of resulting clusters in advance.
The Elbow Method. You can use this method not only for K-Means or Hierarchical clustering algorithms but you can also use this for others who require the number of clusters at first.
K Means Clustering In R Algorithm And Practical Examples Datanovia Sum Of Squares Principal Component Analysis Algorithm

How To Automatically Determine The Number Of Clusters In Your Data And More Data Science Cen Data Science Exploratory Data Analysis Collaborative Filtering

How To Determine The Optimal K For K Means By Khyati Mahendru Analytics Vidhya Medium



Comments
Post a Comment